AI 시대의 학습 윤리: 도구 활용과 사고 위임의 경계
들어가며
AI가 교육 현장에 들어오면서 새로운 질문이 생겼다. "어디까지가 허용되는 도구 활용이고, 어디서부터가 부정행위인가?"
이번 학기 프로그래밍 수업에서 AI 사용을 허용한 평가의 기회가 있었다. 대신 학생들은 자신이 사용한 프롬프트를 제출해야 했고, 나는 결과물뿐 아니라 프롬프트까지 함께 읽었다. 그 과정에서 기준이 하나 또렷해졌다.
AI 사용의 윤리 기준은 'AI를 썼냐/안 썼냐'가 아니다. ① 내가 조건을 세웠는가, ② 실행·그래프·데이터로 검증했는가, ③ 관찰을 내 언어로 썼는가에 달려 있다.
평가 문제 소개
학생들에게 주어진 문제는 두 로봇의 탐색 전략을 비교하는 것이었다.
대회장은 1차원 필드이며, 위치 x에 따른 보물의 가치 V(x)가 주어진다. 이 지형에는 두 개의 봉우리가 있다. 작은 봉우리는 x=4 근처에, 큰 봉우리는 x=15 근처에 있다.
그림 1. 보물 가치 지형 V(x): x≈4의 작은 봉우리와 x≈15의 큰 봉우리
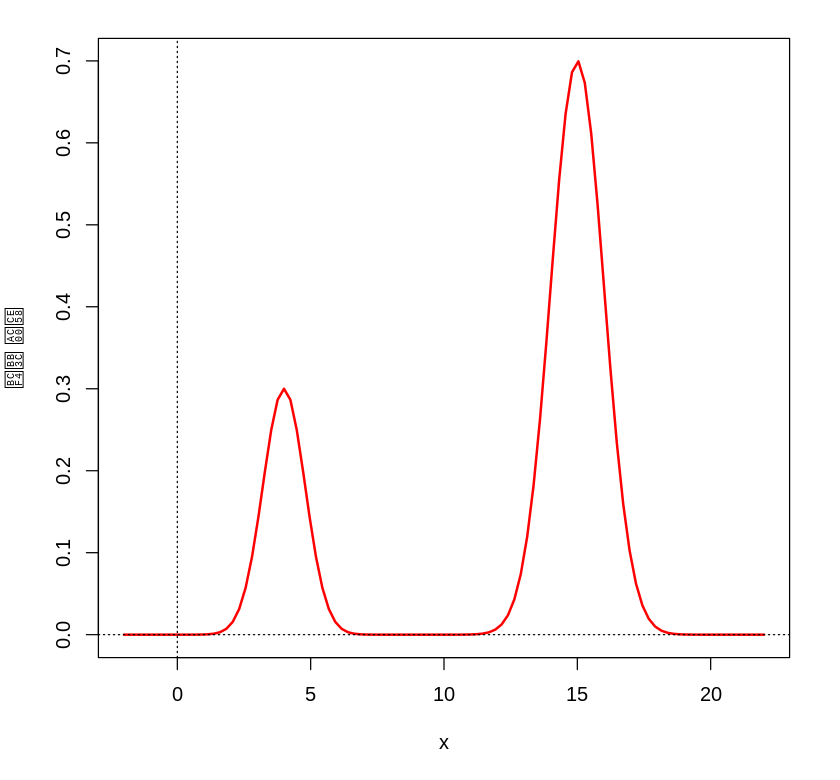
팀 A 로봇(그리디)은 "현재보다 좋은 곳으로만 이동"한다. 후보지의 가치가 현재보다 높으면 이동하고, 그렇지 않으면 절대 이동하지 않는다.
팀 B 로봇은 전략이 비공개다. 학생들은 블랙박스 코드를 실행하여 팀 B의 이동 데이터를 얻고, 히스토그램과 경로 그래프를 통해 팀 B의 전략을 역으로 분석해야 한다.
윤리의 핵심: 결과물의 '주인'은 누구인가
AI를 어떻게 사용하느냐에 따라 결과물의 주인이 달라진다. 이번 평가에서는 세 가지 영역에서 윤리적 경계가 갈렸다.
1) 코드 작성: "코드 짜줘"는 위험하고, "조건을 내가 정한다"가 안전하다
나쁜 프롬프트는 문제를 통째로 복사해서 "코드 짜줘"라고 하고, 결과를 확인하지도 않고 그대로 제출하는 것이다. 이 경우 학생은 문제의 조건을 이해했는지 증명할 방법이 없다.
좋은 프롬프트는 조건을 명확히 제시하고 대화하는 것이다. 예를 들어 아래 프롬프트는 '문제를 읽고 조건을 파악한 흔적'이 남는다.
"현재 위치 x, xcand = x + N(0,2)에서 난수 생성, v(xcand)와 v(x)를 비교해서 전자가 크면 이동, 그렇지 않으면 제자리. 현재 위치 x를 저장하는 for문 작성해줘. 반복 횟수는 10000번, set.seed(20251217), 탐색 범위는 2로 해줘"
핵심은 규칙(이동 조건) + 재현성(seed) + 반복 수가 명시되어 있어, 실행 결과가 맞는지 틀린지 본인이 검증할 수 있다는 점이다. 이건 "사고를 위임"한 게 아니라 "구현을 도구로 처리"한 것이다.
2) 개념 이해: "답 줘"가 아니라 "왜?"를 묻는 순간, 내 것이 된다
나쁜 프롬프트는 문제 전체를 복사해서 "문제 풀어줘"라고 하는 것이다. AI가 "0.8입니다", "0.1입니다"라고 답하면 그대로 적는다.
좋은 프롬프트는 "이게 무슨 의미야?", "왜 이렇게 설계된 거야?"라고 묻는 것이다. AI가 설명해주면 그걸 이해하고, 이해한 것을 자기 언어로 다시 푼다.
한 학생의 답안을 보자.
[문제 4] 팀 B의 이동 규칙 완성
팀 B는 현재 위치보다 가치가 낮은 곳(나쁜 곳)이라도, 그 가치가 현재와 얼마나 차이 나는지에 따라 확률적으로 이동을 결정합니다.
이동 확률 결정 공식: P = V(x_cand) / V(x)
이 공식에 따르면, 후보지의 가치가 현재 가치와 비슷하다면(차이가 적으면), 분자와 분모가 비슷해져서 확률(P)이 1에 가까워집니다. 후보지의 가치가 현재보다 형편없다면(차이가 크면), 분자가 작아져서 확률(P)이 0에 가까워집니다.
[문제 5] 공식 검증
검증 1: V(x_cand) = 0.8, V(x) = 1.0일 때
P = 0.8 / 1.0 = 0.8 → 80%의 확률로 이동
해석: 현재보다 가치가 떨어지지만(1.0 → 0.8), 큰 차이가 아니므로 높은 확률로 이동을 허용합니다.검증 2: V(x_cand) = 0.1, V(x) = 1.0일 때
P = 0.1 / 1.0 = 0.1 → 10%의 확률로 이동
해석: 현재보다 가치가 급격히 떨어지므로(1.0 → 0.1), 매우 낮은 확률로만 이동을 허용합니다.최종 결론: 팀 B의 승리 비결
팀 B는 "손해를 감수하는 용기"를 가졌지만, 그 용기는 무모함이 아니었습니다. 그들은 "조금 손해 보는 길은 과감하게 가보고, 너무 터무니없는 길은 피하는" 합리적인 확률 규칙을 통해, 팀 A가 갇혀버린 작은 언덕(국소 최적해)을 탈출하여 가장 높은 산(전역 최적해)을 찾을 수 있었습니다.
이 답안이 좋은 이유는 세 가지다.
첫째, 공식을 단순히 쓰는 게 아니라 "왜 이렇게 설계되었는지"를 설명했다. "분자와 분모가 비슷해져서", "분자가 작아져서"라는 표현은 공식의 구조를 이해한 사람만 쓸 수 있다.
둘째, 숫자만 쓰는 게 아니라 "해석"을 붙였다. "80%"가 아니라 "큰 차이가 아니므로 높은 확률로 이동을 허용합니다"라고 썼다.
셋째, 마지막에 자기 언어로 정리했다. "손해를 감수하는 용기, 하지만 무모함이 아닌"이라는 표현은 AI가 준 것일 수도 있다. 하지만 이 학생은 "답 줘"가 아니라 "왜?"를 물었고, 이해한 것을 자기 언어로 번역한 것이다.
3) 의견/설명 작성: "내 생각을 대신 써줘"는 도구가 아니라 위임이다
나쁜 프롬프트는 이런 것이다.
" 대학생이 생각할법한 말투와 개념을 가지고 답을 내주라"
"대학생이 쓴것처럼 수정좀"
"여기에 학생 본인의 생각이 들어갈수있게해줘"
이것은 도구 활용이 아니다. 본인의 사고 과정 자체를 AI에게 맡긴 것이다. "내 생각을 대신 써줘"라고 요청하면, 그 결과물은 아무리 그럴듯해도 본인의 생각이 아니다.
좋은 방법은 직접 데이터를 보고 자기 언어로 쓰는 것이다.
"σ가 너무 작을 때(0.5)는 한 번에 이동할 수 있는 거리가 너무 짧아서, x=4 봉우리에서 시작하면 작은 걸음으로만 움직이므로 x=4와 x=15 사이의 골짜기(약 11 단위 거리)를 건너기가 거의 불가능합니다."
이 답변에는 "x=4", "x=15", "약 11 단위 거리"라는 구체적인 숫자가 있다. 직접 히스토그램을 보고, 두 봉우리 사이의 거리를 계산한 사람만 쓸 수 있는 문장이다.
여기에 자기만의 해석을 더한 학생도 있었다.
"보폭이 큰 로봇은 성급하여 광자에 가깝고, 보폭이 작은 로봇은 견자에 가깝다. 그러나 우리는 그 사이의 sd를 선택하여 중행자의 모습을 보여주어야 한다."
데이터를 보고, 거기에 자기만의 지식과 연결을 더한 것이다. 이것은 AI가 절대 생성할 수 없는 문장이다.
AI가 데이터를 보지 않고 쓴 답변의 특징
AI는 데이터를 직접 실행하지 않는다. 그래서 AI가 생성한 답변에는 특징적인 허점이 있다.
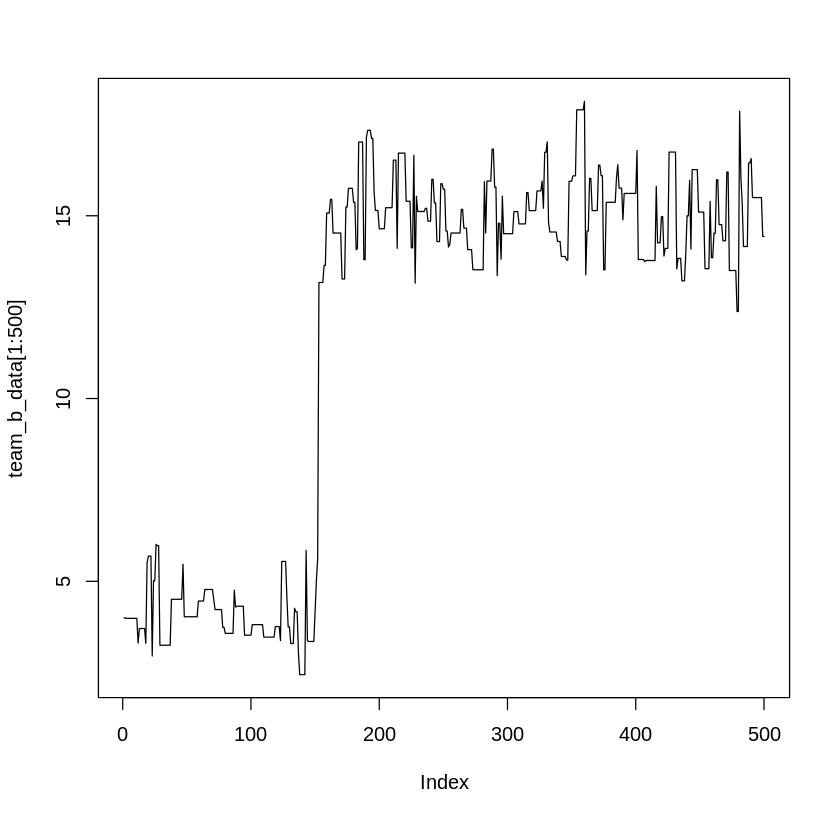
예를 들어, AI에게 팀 B 로봇의 경로를 물어보면 "처음 500회 동안은 x=4 근처에 머물다가..."라고 그럴듯하게 대답한다. 하지만 이건 거짓이다. 실제로 이 시드 넘버에서 코드를 돌려보면, 153번째에 정확하게 값이 x=13 근처로 튄다. AI 이용자는 "500회"라는 답을 진실인 줄 알지만, 실제 데이터와는 다르다.
그림 2. 팀 A(그리디)의 방문 분포가 x≈4에만 집중 → 작은 봉우리에 고착(지역 최적해)

그림 3. 팀 B의 초기 경로: x≈4 부근을 탐색하다가 153번째에 x≈13으로 점프하는 패턴
그리디 로봇의 경우도 마찬가지다. 어차피 랜덤하게 뽑았기 때문에 어떤 시드에서는 값이 왔다 갔다 할 수 있고, 어떤 시드에서는 4만 줄곧 찍힐 수도 있다. 데이터를 직접 보지 않으면 어떤 말도 하기 어렵다. AI가 준 답을 그대로 쓰면 안 되는 이유다.
데이터 관찰 없이 쓴 글은 "Local Optima / Global Optima" 같은 용어로 그럴듯하게 말할 수 있지만, 구체적인 위치나 패턴이 빠지거나 틀리기 쉽다.
왜 데이터에 기반해서 글을 써야 하는가
첫째, AI는 데이터를 보지 않고도 그럴듯한 분석을 생성할 수 있다. 데이터 기반 글은 본인이 실제로 분석을 수행했다는 증거가 된다.
둘째, 데이터 분석가의 핵심 역량은 데이터를 보고 패턴을 발견하는 것이다. 일반적인 이론은 AI에게 물어봐도 되지만, "이 데이터에서 무엇이 보이는가?"는 본인만 할 수 있다.
셋째, 구체적인 숫자는 거짓말을 하기 어렵다. "x=4와 x=15 사이의 골짜기(약 11 단위 거리)를 건너기 어렵다"는 실제 그래프를 봐야 자연스럽게 쓸 수 있다.
결론: AI 시대의 학습 윤리
"실행하지 않고, 그래프를 보지 않고, 데이터를 보지 않고 말할 수 있는 것은 아무것도 없다."
AI에게 코드를 요청하는 것은 괜찮다. AI에게 "이게 무슨 의미야?"라고 물어보는 것도 괜찮다. 하지만 그 다음이 중요하다. AI가 설명해주면 그걸 완벽하게 이해하고, 이해한 것을 내 언어로 다시 풀어야 한다.
"답 줘"로 끝나면 그건 AI의 답이다. "이게 뭐야?", "왜 이렇게 되는 거야?", "그러면 이런 의미야?"라고 대화하면서 만들어가면, 그건 내 답이 된다.
AI는 도구다. 도구는 사용하되, 생각은 본인이 해야 한다.
부록: 좋은 프롬프트 체크리스트
- 규칙을 내 말로 다시 썼는가? (입력/조건/제약)
- 재현성을 명시했는가? (seed, 반복 수)
- 산출물을 지정했는가? (그래프/표/요약)
- 검증 기준을 넣었는가? ("무엇이 보이면 맞는가?")
'AI와 교육의 방향' 카테고리의 다른 글
| AI 시대, 어떤 인재를 원하는가 (1) | 2026.01.23 |
|---|---|
| AI를 써서 데이터를 다룰 때, 무엇이 나의 것으로 남는가 (0) | 2026.01.05 |
| AI를 허용한 평가에서 주의할 점 (0) | 2026.01.05 |
| AI 시대의 학습 윤리-프롬프트 허용 수업의 평가 규칙(허용/경고/부정행위) (0) | 2026.01.02 |
| 시대 별 디지털 교육과 수학교육 (2) | 2025.07.26 |